
pdf2Data
pdf2Data는 구조화되고 재사용 가능한 형식으로 문서에서 데이터를 쉽게 인식 하고 추출하는 솔루션입니다. Java와 C#(.NET), Docker 및 CLI 버전으로 사용할 수 있습니다.
템플릿에서 정의한 선택 규칙(Selection Rules)을 기반으로 PDF 문서 내의 데이터를 지능적으로 인식하는 프레임워크를 제공합니다. 이 솔루션은 문서 인식을 위해 광범위한 교육이 필요한 AI 기반의 대체 솔루션에 비해 큰 이점을 제공합니다.
또한, 직관적인 브라우저 기반의 pdf2Data Editor(Docker 이미지로도 사용 가능) 덕분에 마케터부터 정보 관리자, HR 직원에 이르기까지 누구나 템플릿을 만들고 업데이트 할 수 있습니다. 개발자가 아니라도 pdf2Data를 사용하는 이점을 누릴 수 있습니다.
pdf2Data는 어떤 제품인가요 ?
pdf2Data는 PDF 데이터 추출을 위한 사용자 친화적인 테플릿 기반의 협업 가능한 솔루션입니다.
pdf2Data는 다음 세가지 모듈로 구성됩니다 :
- pdf2Data Manager,
- pdf2Data Editor,
- pdf2Data SDK.
이 컴포넌트로 원하는 정보를 Workflow에 통합하는 것부터 엄격한 접근 관리를 통해 시간 경과에 따른 구문 분석 규칙을 유지 관리하고 업데이트 하고, 대용량 문서 처리의 과중한 작업 수행에 이르기까지 데이터 추출 프로세스의 모든 업무를 처리합니다.
PDF 문서가 아닌 경우에는 iText가 해결합니다. iText의 애드온 기능인 pdfOCR은 스캔한 문서와 이미지를 pdfData2에서 처리할 수 있는 PDF(또는 장기 보관 규정을 준수하는PDF/A-3u)로 변환합니다.
pdf2Data 혜택
왜 pdf2Data를 사용하나요 ?
데이터는 중요한 상품이며 PDF 문서 안에 잠겨 있는 것보다 더 많은 데이터를 얻을 수 있습니다. 이 데이터를 수동으로 수집하면 입력 오류나 고려해야 할 보안 문제의 위험과 함께 시간과 리소스가 많이 소요될 수 있습니다.
pdf2Data를 사용하면 데이터 캡처 프로세스를 자동화하고 안전한 방식으로 데이터를 추출할 수 있습니다. 단일 참조 파일에서 템플릿을 작성하기 때문에 pdf2Data를 사용하면 예측이 가능한 동일 형식의 모든 PDF에서 데이터를 인식 하고 추출할 수 있습니다. 이 추출 접근 방식은 인식 모델을 교육하기 위해 대규모 데이터 세트가 필요 없으며 처음부터 가장 높은 수준의 신뢰성을 제공합니다.
pdf2Data 템플릿은 유연하고 재사용이 가능하기 때문에 각각의 새 문서에 대한 추출 규칙을 처음부터 재정의할 필요가 없습니다. 대신 기존 템플릿을 쉽게 재 사용 혹은 수정하여 새로운 또는 다른 레이아웃의 문서를 처리할 수 있습니다.
사용자 친화적이며 빠릅니다.
pdf2Data는 PDF 데이터의 잠금을 해제하고 재사용하는 시간을 줄입니다. pdf2Data Manager를 사용하면 추출 규칙의 유지 관리와 업데이트를 빠르고 쉽게 할 수 있습니다.
pdf2Data Editor를 사용하여 템플릿에서 추출을 원하는 정보를 정의만 하면 pdf2Data SDK를 통해 만들어 즉시 사용할 수 있습니다.
예측 가능한 구조화로 모든 문서를 처리합니다.
송장, 양식, 구매 주문서, 은행 명세서, 보고서 등이 있더라도 걱정하지 마십시오. 문서 내부의 관계성을 예측할 수 있으면 작업 과정(Workflow)에서 PDF를 처리할 수 있습니다.
간단하게 통합합니다.
pdf2Data는 개방형 표준을 사용하여 통합을 촉진하므로 기존 Workflow에 쉽고 빠르게 통합할 수 있습니다. 여기에는 Java와 .NET(C#)용 개발자 중심의 SDK와 Command Line 인터페이스, REST API가 포함된 Docker 이미지가 포함됩니다. 21세기를 위한 진정한 데이터 처리 제품입니다.
AI 기반의 솔루션보다 뛰어나다?
컨텐츠 인식은 사용자의 추출 템플릿을 기반으로 하기 때문에 pdf2Data는 데이터를 인식하고 추출하기 위한 사전 교육이 필요하지 않습니다. 데이터 인식은 각 데이터 필드에 대해 미리 정의하는 여러 가지 규칙을 사용합니다. 일반적인 규칙은 PDF 문서의 모든 세부 정보를 통해 정확하고 유효한 데이터 추출을 보장하기 위해 결합되어 사용됩니다.
pdf2Data 주요 기능
pdf2Data는 인보이스(Invoice)나 상업용 문서 같은 동일한 형식으로 생성된 모든 PDF에 사용되는 템플릿에서 영역(Areas), 글꼴(Fonts), 패턴 또는 관심표(Tables of Interest)를 정의하여 동작합니다.
그런 다음, 데이터 필드 선택기(Data Field Selecors)로 관심 영역을 정의할 수 있습니다. 각각의 선택기(Selector)는 중요한 정보를 식별하기 위해 서로 다른 방법을 사용합니다. 선택기(Selector)를 결합하여 요구 사항에 따라 데이터 식별과 캡처를 미세하게 조정할 수도 있습니다.
데이터는 추출된 컨텐츠의 페이지 좌표에 액세스하여 추가 처리를 위해 구조화 되고 재사용 가능한 형식으로 출력됩니다.
PDF 문서에서 데이터 추출
텍스트, 이미지 및 기타 컨텐츠 인식을 위해 iText의 고화질 컨텐츠 추출(High-fidelity Content Extraction) 기능을 활용하십시오.
직관적인 추출 설정
pdf2Data는 확장 및 특화 가능한 유연성과 함께 포괄적이며 즉시 사용 가능한 기능을 제공합니다. 또한, 손쉬운 통합과 개방형 표준에 중점을 두고 있습니다.
능률적인 추출 템플릿 사용
관심 영역과 선택 규칙을 정의하여 필요한 컨텐츠를 정확하게 얻을 수 있습니다.
PDF와 데이터 Workflow로 통합
추출된 컨텐츠의 페이지 좌표에 대한 액세스를 통해, 추가 처리를 위해 구조화 되고 재사용 가능한 형식으로 데이터를 출력합니다.
pdf2Data로 무엇을 할 수 있을까요 ?
등록 양식, 송장 등과 같이 비즈니스에서 처리해야 하는 많은 PDF 문서는 공통된 구조로 이루어 집니다. 송장 문서의 예를 보면, 송장 번호, 공급자 주소, 구매 주문 번호 및 유사한 문서 요소가 한 곳에 있는 경향이 있으며, 항목 설명, 수량 및 항목 비용과 같은 내용만 변경됩니다. 예제 송장을 템플릿으로 사용하여 캡처하려는 데이터가 있는 문서 영역을 정의하고 분류할 수 있습니다.
pdf2Data는 추출하려는 컨텐츠에 해당하는 템플릿의 영역과 규칙을 정의하여 PDF 문서에서 데이터를 쉽게 추출할 수 있는 방법을 제공합니다. 그런 다음, 해당 템플릿과 일치하는 모든 후속 문서를 처리하기 위해 pdf2Data SDK로 구문 분석 하기 전에 템플릿을 다른 문서와 함께 시각적으로 검증하여 데이터가 정확하게 인식되었는지 확인할 수 있습니다.
AI 기반의 솔루션과 달리 인식 프로세스를 교육하기 위해 수백 개의 샘플과 집중적인 감독 과정이 필요 없습니다. 컨텐츠 인식은 설정한 템플릿을 통해 제어되므로 데이터 추출 전에 학습(Training)이 필요하지 않습니다. 모든 문서의 데이터 추출 활성화를 위해 예제 문서 하나만 있으면 됩니다.
AI 인식에는 단점도 있습니다. 필요한 출력에 대한 변경 사항(예, 새로운 필드 추가)은 모델을 재교육해야 하며, 다국어 지원은 기껏해야 매우 낮은 수준입니다. 동일한 레이아웃을 사용하지만 다른 언어로 된 컨텐츠의 문서는 거칠고 일관성 없는 결과를 제공할 수 있습니다.
반면에 pdf2Data는 이런 단점이 없습니다. 템플릿을 쉽고 빠르게 수정할 수 있으며 언어를 탁월하게 지원합니다. 또한, 다른 데이터 추출 솔루션의 주요 단점 중 하나인 강력한 테이블 인식 기능을 제공합니다.
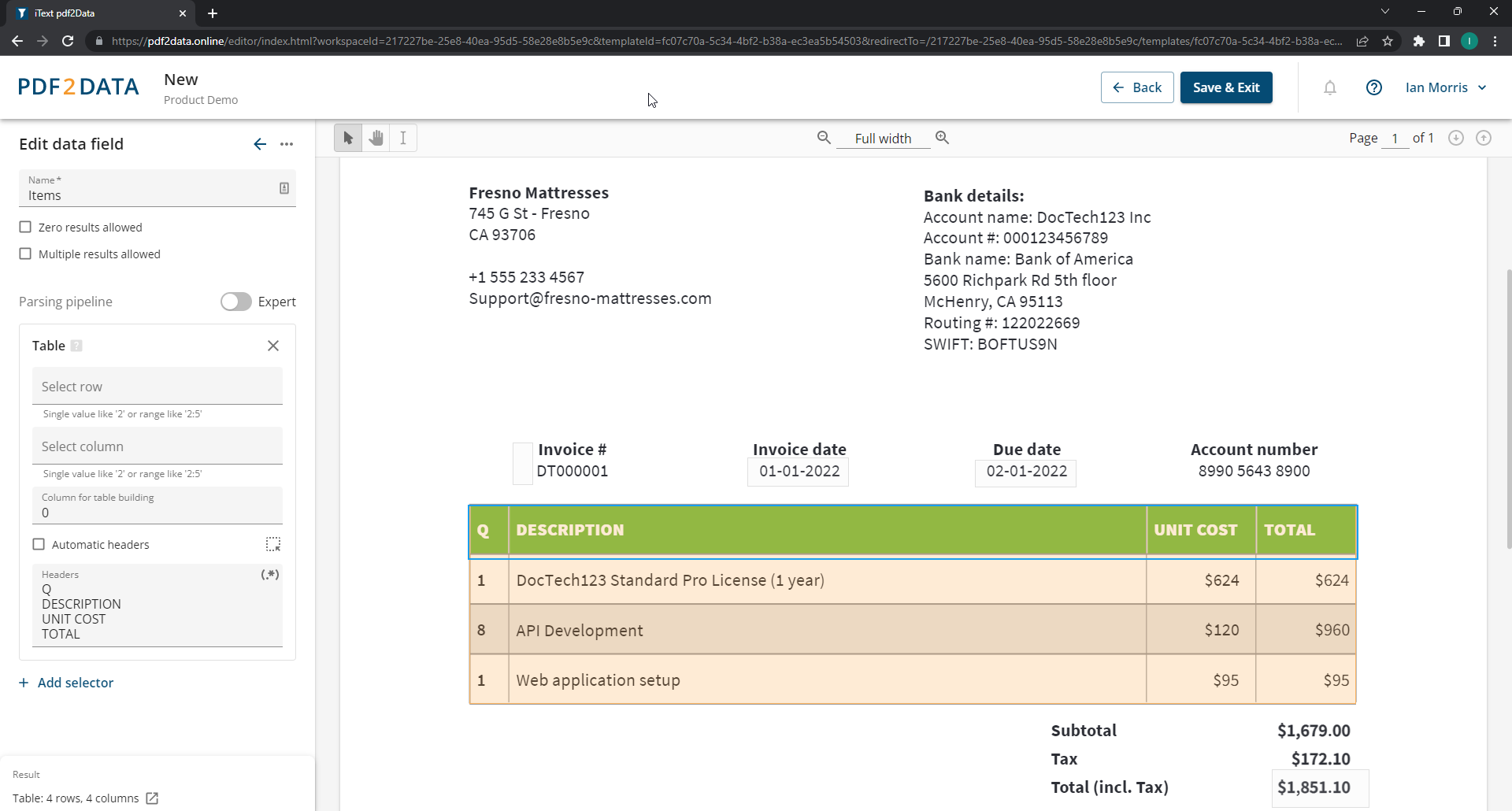
pdf2Data는 어떻게 동작하나요 ?
직관적인 브라우저 기반의 pdf2Data Editor를 사용하면 데이터 추출을 위한 템플릿을 쉽게 만들 수 있습니다. 관심 영역에 대한 데이터 필드 선택기(Data Field Selectors)를 정의하여 샘플 문서를 기반으로 템플릿 PDF를 생성만 하면 됩니다. 선택기(Selector)는 추출하려는 다양한 유형의 컨텐츠를 인식하도록 설정 가능한 규칙을 말합니다.
pdf2Data에는 텍스트와 이미지, 또는 바코드와 같은 기타 컨텐츠를 지능적으로 인식하고 추출하도록 선택할 수 있는 약 24 개의 선택기(Selector)가 있습니다. 다음 사항을 인식하도록 선택기(Selector)를 설정할 수 있습니다 :
- 페이지 범위와 페이지 내의 위치(page range and the position on the page)
- 특정 폰트, 폰트 색상 및 텍스트 패턴(specific font styles, font color, and text patterns)
- 데이터 옆의 고정 키워드(fixed keywords next to the data)
- 테이블 구조의 자동 인식(automatic recognition of table structures)
또한, 많은 선택기(Selector)를 결합하여 감지 매개변수(Detection Parameters)를 미세하게 조정할 수 있습니다.
추출 템플릿은 템플릿과 일치하는 모든 PDF의 구문을 분석하는데 사용됩니다. pdf2Data Editor를 사용하여 문서를 업로드하고, 추출 템플릿을 테스트하며, 데이터 필드 선택기(Data Field Selectors)가 필요한 데이터를 인식하도록 정확하게 설정되었는지 확인할 수 있습니다.
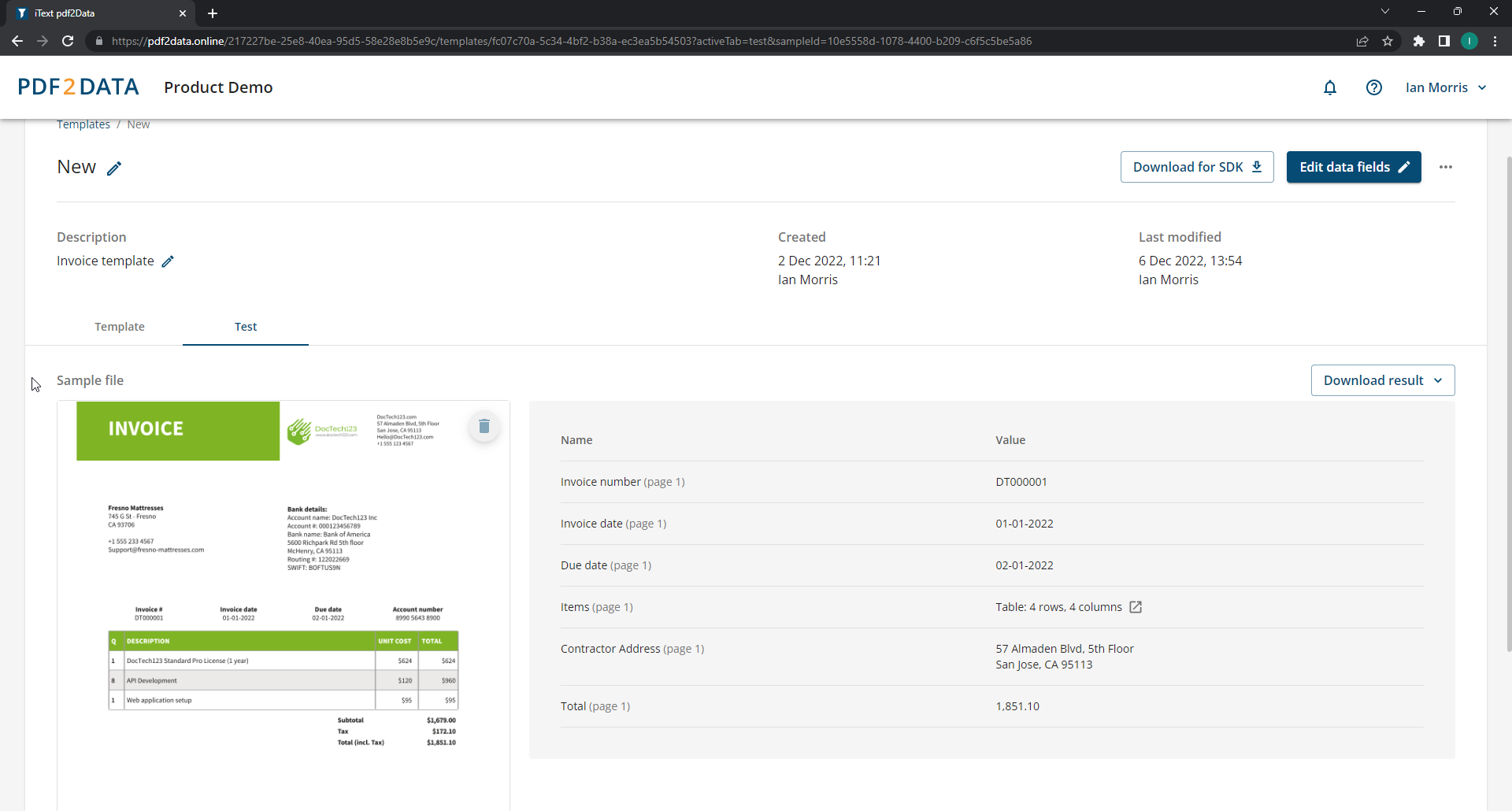
추출 템플릿을 설정하면 이를 테스트하여 정확한 데이터 캡처와 추출을 보장할 수 있습니다.
문서 생성 솔루션인 iText DITTO와 마찬가지로 pdf2Data를 사용하면 개발자뿐만 아니라 누구나 iText의 강력한 PDF 기능을 활용할 수 있습니다. 문서 템플릿을 간단하게 만들거나 수정하여 데이터를 인식하고, 자동으로 추출한 다음, 필요한 사람이 쉽게 재사용할 수 있습니다. 스마트하고 구조화된 방식으로 문서에서 데이터를 지능적으로 추출함으로써 데이터를 분석, 보고서 또는 원하는 용도로 쉽게 용도 변경할 수 있습니다.
개발자는 pdf2Data Manager/Editor를 pdf2Data SDK에 배포하고 문서 작업(Workflow)에 통합만 하면 됩니다. 이후, 템플릿 설정과 데이터 확인 및 pdf2Data로 바로 작업할 수 있습니다.
지식 베이스(Knowledge Base)에서 모든 데이터 필드 선택기에 대한 설치 지침과 Tutorials 및 상세 문서 자료를 찾을 수 있습니다.
Demo를 요청하십시오.
iText 엔지니어링 팀의 안내 데모를 통해 pdf2data의 성능을 확인해 보십시오.
데모를 요청하면 영업일 기준 2일 이내에 연락하여 자세한 내용을 문의하고 연습 시간을 정하게 됩니다. 여기에 요청 사항을 제출하면 데모 링크가 곧바로 전송됩니다. 연락을 받지 못한 경우에는 “스팸”이나 “정크 메일” 폴더를 확인하십시오.
Resources
여기에서 pdf2Data 컴포넌트 설치 및 설정, 사용에 필요한 리소스를 찾을 수 있습니다. Pdf2Data의 작동 방식에 대한 데모를 찾고 있으시면 해당 기능에 대한 프레젠테이션을 받을 수 있는 데모를 요청하십시오.
iText Ditto : 데이터 구동형 템플릿 기반의 PDF 생성기(Generator)
이제 데이터를 추출하였습니다. 템플릿 기반의 솔루션에 삽입하십시오.
템플릿 기반의 데이터 추출이 완료되었고 노이즈가 제거되었습니다. 데이터에서 PDF를 생성하는 템플릿 기반의 협업 솔루션에 관심이 있으신지요 ?
iText를 사용할 준비가 되셨나요 ?
항상 그렇듯이, 기술적인 문의가 있는 경우 유효한 지원 구독라이센스(Subscription)로 지원팀에 문의하거나 Stack Overflow의 커뮤니티 지원(Community Support) 페이지를 방문하여 오픈 소스 AGPL 사용자를 위한 답변과 정보를 확인할 수 있습니다.
