

데이터 과학 및 AI 파이프라인 가속화
AI 키트는 데이터 과학자, AI 개발자 및 연구원에게 친숙한 Python* 도구 및 프레임워크를 제공하여 인텔® 아키텍처에서 종단 간 데이터 과학 및 분석 파이프라인을 가속화합니다. 구성 요소는 낮은 수준의 계산 최적화를 위해 oneAPI 라이브러리를 사용하여 빌드됩니다. 이 툴킷은 전처리부터 기계 학습까지 성능을 극대화하고 효율적인 모델 개발을 위한 상호 운용성을 제공합니다.
이 툴킷을 사용하여 다음을 수행할 수 있습니다.
- intel XPU에 대한 고성능 딥 러닝 교육을 제공하고 TensorFlow* 및 PyTorch*용 intel®®에 최적화된 딥 러닝 프레임워크, 사전 학습된 모델 및 저정밀 도구를 사용하여 AI 개발 워크플로에 빠른 추론을 통합합니다.
- intel에 최적화된 컴퓨팅 집약적 Python* 패키지, Modin*, scikit-learn* 및 XGBoost를 통해 데이터 전처리 및 기계 학습 워크플로우를 위한 드롭인 가속화를 달성하십시오.
- intel에서 분석 및 AI 최적화에 직접 액세스하여 소프트웨어가 원활하게 함께 작동하도록 하십시오.





AI 키트로 구동되는 데이터 과학 워크스테이션
OEM(주문자 상표 부착 방식) 파트너는 랩톱, 데스크톱 또는 타워 구성인 인텔 기반 데이터 과학 워크스테이션을 제공합니다®.
- ® 데이터 과학 작업에 적합한 인텔 코어™ 또는 인텔® 제온® 프로세서
- 대용량 데이터 세트의 메모리 내 처리를 가능하게 하는 대용량 메모리 용량으로 데이터를 정렬, 필터링, 레이블 지정 및 변환하는 데 필요한 시간이 단축됩니다.
- 매우 큰 용량의 워크로드 및 메모리 내 데이터베이스를 위한 DRAM에 대한 경제적인 대안을 제공하는 인텔® Optane™ 영구 메모리
- 인텔 아키텍처에서 종단 간 AI 및 데이터 분석 파이프라인을 가속화하는 응용 프로그램 및 라이브러리가 포함된 AI 키트 소프트웨어
데이터 과학 워크스테이션
AI 키트는 일부 OEM 데이터 과학 워크스테이션에 사전 설치되어 제공됩니다. 설치 안내서를 사용하여 워크스테이션에서 AI 키트를 다운로드합니다.
- Dell Precision* 데이터 과학 워크스테이션: 설치 안내서를 참조하십시오.
- Z by Hewlett Packard Enterprise* 데이터 과학 워크스테이션: AI 키트 구성 요소는 데이터 과학 환경을 사용자 정의하기 위한 애플리케이션인 HP Data Science Stack에 의해 Z를 통해 미리 로드됩니다.
- 레노버 씽크스테이션* 및 씽크패드* P 시리즈 워크스테이션: 출하 시 설치.
벤치 마크
이러한 벤치마크는 AI 키트의 성능 기능을 보여줍니다.




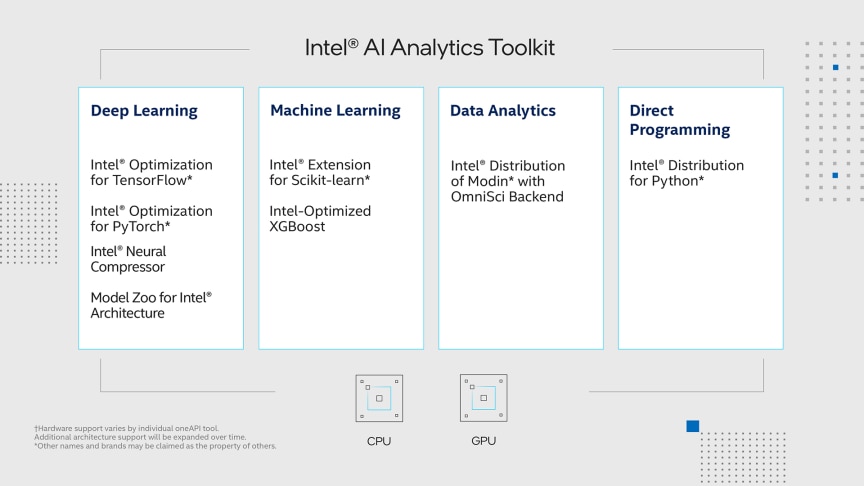
기능
최적화된 딥 러닝
- TensorFlow 및 PyTorch를 포함한 인기 있는 인텔에 최적화된 프레임워크를 활용하여 인텔 아키텍처의 모든 기능을 사용하고 교육 및 추론을 위한 고성능을 제공합니다.
- 인텔에서 최상의 성능을 위해 최적화한 오픈 소스, 사전 학습된 기계 학습 모델을 사용하여 개발을 가속화합니다.
- 저정밀도 최적화를 사용하여 성능, 모델 크기 또는 메모리 풋프린트와 같은 추가 목표와 함께 자동 정확도 기반 튜닝 전략을 활용하십시오.
데이터 분석 및 기계 학습 가속화
- 인텔 아키텍처에 최적화된 scikit-learn 및 XGBoost의 알고리즘으로 기계 학습 모델의 정확도와 성능을 향상시킵니다.
- 클러스터로 효율적으로 확장하고 Scikit-learn용 Intel Extension을 사용하여 분산 기계 학습을 수행합니다.
고성능 파이썬*
- AI 및 데이터 분석을 위한 가장 인기 있고 빠르게 성장하는 프로그래밍 언어를 인텔 아키텍처에 최적화된 기본 명령어 세트로 활용하십시오.
- 기존 Python 코드에 대한 드롭인 성능 향상을 사용하여 더 큰 과학 데이터 세트를 더 빠르게 처리합니다.
- 고효율 멀티스레딩, 벡터화 및 메모리 관리를 달성하고 클러스터 전체에서 과학적 계산을 효율적으로 확장할 수 있습니다.
다중 노드 데이터 프레임에 걸쳐 단순화된 크기 조정
- 매우 가벼운 병렬 DataFrame인 Intel® Distribution of Modin*을 사용하여 단 한 줄의 코드 변경만으로 팬더 워크플로를 멀티코어 및 멀티 노드로 원활하게 확장하고 가속화할 수 있습니다.
- OmniSci와 같은 고성능 백엔드로 데이터 분석을 가속화합니다.
뉴스





포함된 항목
Intel® Optimization for TensorFlow*
Google*과 협력하여 TensorFlow는 성능을 극대화하기 위해 oneDNN의 프리미티브를 사용하여 인텔 아키텍처에 직접 최적화되었습니다. 이 패키지는 CPU 사용 설정(–config=mkl)으로 컴파일된 최신 TensorFlow 바이너리 버전을 제공합니다.
Intel® Optimization for PyTorch*
Facebook*과 협력하여 이 인기 있는 딥 러닝 프레임워크는 이제 인텔의 많은 최적화와 직접 결합되어 인텔 아키텍처에서 우수한 성능을 제공합니다. 이 패키지는 CPU용 최신 PyTorch 릴리스의 바이너리 버전을 제공하고, 효율적인 분산 교육을 위해 oneCCL을 사용하여 인텔의 확장 및 바인딩을 추가합니다.
Model Zoo for Intel® Architecture
intel에서 intel 제온 스케일러블 프로세서에서 실행되도록 최적화한 많은 인기 있는 오픈 소스 기계 학습 모델에 대한 사전 학습된 모델, 샘플 스크립트, 모범 사례 및 단계별 자습서에 액세스합니다.
이 오픈 소스 Python 라이브러리를 사용하여 intel에서 최적화한 여러 딥 러닝 프레임워크에 통합된 저정밀도 추론 인터페이스를 제공합니다.
Intel® Extension for Scikit-learn*
단일 노드 및 다중 노드에서 intel® CPU 및 GPU에서 scikit-learn 응용 프로그램의 속도를 원활하게 높일 수 있습니다. 이 확장 패키지는 기계 학습 알고리즘의 속도를 높이면서 intel® oneAPI 데이터 분석 라이브러리(oneDAL)를 기본 솔버로 사용하도록 scikit-learn 추정기를 동적으로 패치합니다. 툴킷에는 필요한 모든 패키지와 함께 설치된 포괄적 인 Python 환경을 제공하기 위해 stock scikit-learn도 포함되어 있습니다. 이 확장은 scikit-learn의 마지막 네 가지 버전까지 지원하며 기존 패키지와 함께 사용할 수 있는 유연성을 제공합니다.
XGBoost Optimized for Intel Architecture
XGBoost 커뮤니티와 협력하여 인텔은 인텔 CPU에서 우수한 성능을 제공하기 위해 많은 최적화를 직접 업스트리밍하고 있습니다. 그라디언트 부스트 의사 결정 트리를 위한 이 잘 알려진 기계 학습 패키지에는 이제 인텔 아키텍처가 모델 교육 속도를 크게 높이고 더 나은 예측을 위해 정확도를 향상시킬 수 있는 원활한 드롭인 가속이 포함되어 있습니다.
팬더 워크플로를 가속화하고 팬더와 동일한 API를 갖춘 이 지능적이고 분산된 DataFrame 라이브러리를 사용하여 다중 노드 전처리를 확장합니다. 이 라이브러리는 백엔드의 OmniSci와 통합되어 분석을 가속화합니다. 이 구성 요소는 툴킷의 Anaconda* 배포판을 통해서만 사용할 수 있습니다. 다운로드하여 설치하려면 설치 안내서를 참조하십시오.
Intel® Distribution for Python*
intel® 성능 라이브러리를 사용하여 빌드된 핵심 Python 수치 및 과학 패키지의 가속화를 통해 더 큰 성능을 달성하십시오. 이 패키지에는 최신 SIMD(단일 명령 다중 데이터) 기능과 멀티코어 실행을 통해 최신 CPU를 완전히 사용할 수 있도록 꾸며진 Python 코드용 적시 컴파일러인 Numba 컴파일러*가 포함되어 있습니다. CPU 코드를 장치 코드에 다시 작성하지 않고도 동일한 프로그래밍 모델인 DPPy(Data Parallel Python)를 사용하여 여러 장치를 프로그래밍할 수 있습니다.
최적화된 통신 패턴을 구현하여 딥 러닝 모델 학습을 여러 노드에 분산합니다.
기계 학습 및 데이터 분석 성능을 향상시킵니다.
Intel® Distribution for Python*
성능에 최적화된 빌딩 블록을 갖춘 인텔 CPU 및 GPU에서 빠른 신경망을 개발합니다.
Intel® DPC++ Compatibility Tool
CPU, GPU 및 FPGA 대상 아키텍처를 위해 C++ 및 SYCL 코드를 컴파일하고 최적화합니다.
Intel® FPGA Add-on for oneAPI Base Toolkit
주요 생산성 알고리즘 및 기능을 통해 데이터 병렬 워크로드의 속도를 높입니다.
Intel® Integrated Performance Primitives
행렬 대수, 고속 푸리에 변환(FFT) 및 벡터 수학을 포함한 수학 처리 루틴을 가속화합니다.
이 고급 스레딩 및 메모리 관리 템플릿 라이브러리를 사용하여 병렬 처리를 단순화합니다.
문서 및 코드 샘플
문서조사
- 설치 가이드: Intel | Anaconda | Docker* | Dell Precision Data Science Workstation
- 패키지 관리자: YUM | APT | Zypper
- 시작 가이드: Linux* | Windows* | Containers
- 릴리스 정보
- CPU에서 TensorFlow 성능 최대화: 추론 워크로드에 대한 고려 사항 및 권장 사항
- Scikit-learn 시작하기
Training









사양
- Intel Xeon processors
- Intel Xeon Scalable processors
- Intel Core processors
Language:
- Python
Operating systems:
- Linux*
Development environments:
- Compatible with Intel® compilers and others that follow established language standards
- Linux: Eclipse* IDE
Distributed environments:
- MPI (MPICH-based, Open MPI)
Support varies by tool. For details, see the system requirements.
도움말 보기
자세한 내용은 일반적인 oneAPI 지원을 참조하세요.
